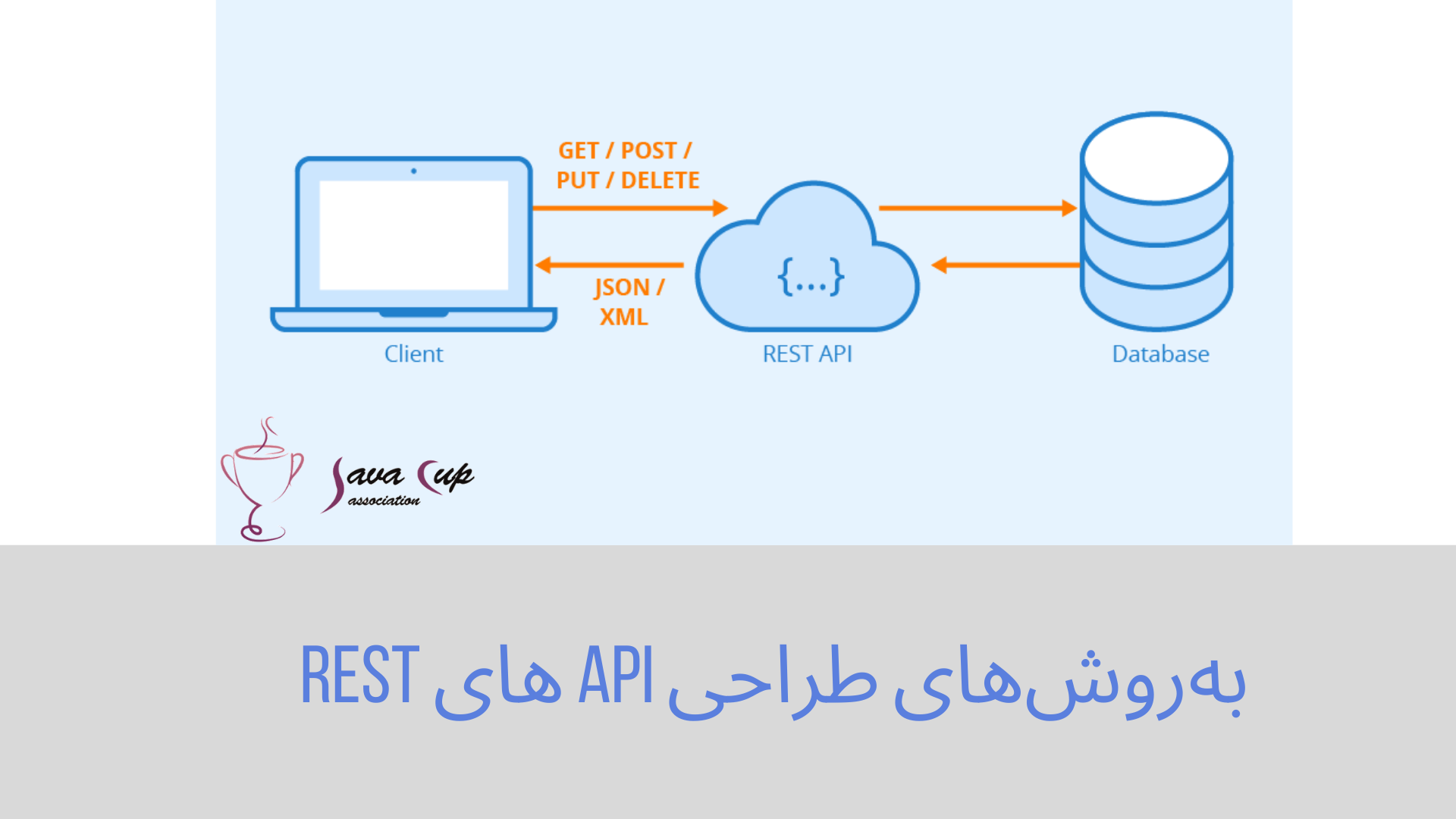
نتیجه طراحی ضعیف APIهای REST غیرقابل استفاده بودن است
به عنوان توسعهدهنده و معمار نرمافزار، دائما در حال فراخوانی و تجمیع سرویسهای مختلف به وسیله APIهای REST هستیم. گاهی اوقات به دلیل طراحی ضعیف یا داکیومنتهای کم، استفاده از این APIها بسیار سخت است. این موضوع باعث میشود تا برنامهنویسان (از جمله من) قادر به استفاده از سرویسهای موجود نباشند و مجبور شوند همان کارکرد را از اول پیادهسازی کنند.
بحثمان را با توضیح REST و اینکه منظور از «طراحی APIهای REST» چیست، شروع میکنیم.
REST چیست؟
در سال ۲۰۰۰ یکی از طراحان اصلی HTTP به نام روی فیلدینگ، یک رویکرد برای معماری سرویسهای وب به نام REST معرفی کرد. (مخفف Representational State Transfer به معنای انتقال بازنمودی حالت.)
توجه داشته باشید که اگرچه در این مقاله، پیادهسازی REST را با بستر HTTP در نظر میگیریم، اما REST الزاما به HTTP نیاز ندارد. APIهای REST برای دسترسی به یک منبع (مثلا یک فایل یا سرویس) طراحی میشوند. این منبع با URI (شناسنامه منبع یکسان) خود شناخته میشود. استفاده از HTTP به این صورت است که منبعی که URI به آن اشاره میکند توسط HTTP درخواست میشود و بازنماییای از وضعیت فعلی آن برگردانده میشود.
چرا طراحی API اهمیت دارد؟
این سوال زیاد پرسیده میشود و برای پاسخ باید بگویم که APIهای REST راه استفاده از هر سرویس هستند پس باید شرایط زیر را داشته باشند.
- طراحی API باید فهم آسانی داشته باشد تا تجمیع نرمافزار با آن آسان باشد.
- خوب داکیومنت شده باشد تا علاوه بر قواعد نحوی استفاده از API، قواعد معنایی هم قابل فهم باشد.
- استانداردهای موجود مثل HTTP را رعایت کند.
طراحی و پیادهسازی APIهای REST قابل استفاده
ما در تیم فنی، قواعد زیر را رعایت میکنیم تا APIهایمان قابل استفادهتر باشند:
۱. استفاده از اسم در URI
همانطور که بالاتر ذکر شد، APIهای REST برای منابع (فایلها یا سرویسها) طراحی میشوند. بنابراین همیشه باید فرم اسمی داشته باشند. مثلا به جای /createUser از /users استفاده میشود.
۲. مفرد یا جمع بودن
ما معمولا از اسم به شکل جمع استفاده میکنیم اما الزامی به این کار وجود ندارد. ایده اصلی استفاده از اسم جمع به شکل زیر است:
ما روی «یک منبع» از «مجموعهای از منابع» کار میکنیم، بنابراین برای نشان دادن «مجموعه منابع» از جمع استفاده میکنیم. در مثال زیر
GET /users/123
سرور با دریافت این درخواست، بین مجموعه کاربرها دنبال کاربر با id برابر ۱۲۳ میگردد.
همچنین زمانی که میخواهیم یک کاربر جدید بسازیم، باید یک کاربر به «مجموعه فعلی کاربران» اضافه کنیم پس باز هم از جمع استفاده میکنیم:
POST /users
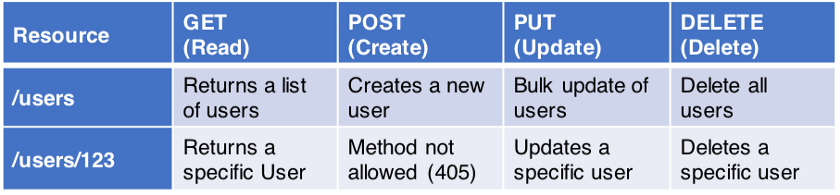
۳. بگذارید متد HTTP، عملیات را مشخص کند
همانطور که در قسمت ۱ گفته شد، مسیر URI باید از اسم منابع تشکیل شود. به این ترتیب، مشخص کردن کاری که رو منبع انجام میشود به عهده متد HTTP (برای مثال GET و POST و PUT و DELETE) است.
در جدول زیر، نمونهای از افعال و متدهای مختلف آورده شده است.
۴. از متدهای Safe درست استفاده کنید (اصل قابل تکرار بودن)
برخی از متدهای HTTP به عنوان امن (Safe) شناخته میشوند، به این معنی که هر تعداد بار از سمت کاربر فراخوانی شوند، نتیجه مشابهی برمیگردانند. این متدها عبارتاند از GET و HEAD و OPTIONS و TRACE.
پس به هیچوجه نباید از GET برای برای پاک کردن یک منبع استفاده کرد. مثلا هیچوقت چنین چیزی طراحی نکنید.
GET /users/123/delete
البته دقت داریم که به این معنی نیست که به این شکل نمیتواند پیادهسازی شود بلکه در این صورت، قواعد HTTP نقض میشود.
پس، از متدهای HTTP براساس عملیاتی که قرار است صورت بگیرد استفاده کنید.
[یادداشت مترجم:در اینجا خوب است به تفاوت متد امن (Safe) و قابلتکرار (Idempotent) پرداخته شود.
اصل Idempotency یا قابل تکرار بودن به این معنی است که هر تعداد بار که از متد استفاده کنیم، نباید در نتیجه تغییری ایجاد شود. اما ممکن است خود منبع تغییر کند مثلا مهر زمانی (timestamp)اش بروز شود.
اما متد امن نباید منبعی سمت سرور را تغییر دهد. مثلا GET به عنوان متد امن نباید چیزی را حذف کند. در این صورت متدهای امن میتوانند کَش شوند یا پیش از درخواست واقعی کاربر لود شوند (prefetch). ابزارهای مختلف مثلا مرورگرها نیز با همین فرضها طراحی میشوند. مثلا این اجازه را دارند که روی لینکهایی که از متدهای امن استفاده میکنند بدون اطلاع کاربر و به منظور prefetch کلیک کنند.
در این مورد بیشتر بخوانید.]
۵. نمایش سلسهمراتب منابع از طریق URI
اگر یک منبع شامل زیربخشهایی هم هست، حتما این را از طریق طراحی API هم نشان دهید. مثلا اگر کاربر تعدادی مطلب دارد و ما میخواهیم یکی از مطالبش را به دست آوریم، API میتواند به این شکل طراحی شود.
/users/123/posts/1
پست ۱ از کاربر با کد 123 را برمیگرداند.
۶. برای APIهای خود نسخه تنظیم کنید
تنظیم نسخه برای API، کمک میکند در عین اینکه قابلیتهای جدید اضافه میکنیم یا قابلیتهای فعلی را بروز میکنیم، سازگاری با گذشته (backward compatibility) برای نسخههای قدیمی را هم حفظ کنیم. راهکارهای متفاوتی برای اینکار وجود دارد اما مهمترین آنها در زیر لیست شدهاند:
استفاده از هِدِرها
دو نوع متفاوت از هدرها (Header) را میتوان استفاده کرد.
۱. هدر سفارشی: هدری مثل X-API-VERSION از سمت کاربر ارسال شود و از این هدر استفاده شود تا درخواست به مسیر صحیح (با ورژن صحیح) برسد.
۲. هدرِ Accept: از هدر Accept استفاده کنید تا ورژن را مشخص کند، مثلا:
Accept: application/vnd.hashmapinc.v2+json
استفاده از URL
نسخه API خود را مستقیما در URL قرار دهید، مثلا:
POST /v2/users
ما استفاده از URL را بر روشهای دیگر ترجیح میدهیم چرا که دید بهتری از منبع با نگاه به URL به ما داده میشود. ممکن است بگویید شاید اصلا یک سرویس خاص در نسخههای مختلف تغییر نکرده باشد، پس چرا باید برای یک منبع خاص چندین URL داشته باشیم؟ در این مورد حق با شماست! برای همین است که من اصرار به روش خاصی ندارم. تیم توسعه باید راه دلخواه خودشان را برای تنظیم نسخه API خود در نظر بگیرند.
۷. مقدار برگشتی
متدهایی که یک منبع جدید میسازند یا منبع فعلی را بروز میکنند (POST و PUT و PATCH) همیشه باید مقدار آپدیتشده منبع را با کد وضعیت مناسب برگردانند.
اگر درخواست POST موفقیتآمیز باشد، یعنی موفق به ساخت منبع جدید شود، باید کد ۲۰۱ را همراه با URI منبع جدید ساختهشده به عنوان هدر Location برگرداند. (مطابق قواعد HTTP.)
۸. فیلتر، جستوجو و مرتبسازی
برای عملیاتهای فیلتر، جستوجو و مرتبسازی، URIهای جدید ایجاد نکنید بلکه سعی کنید URI به شکل ساده خود بماند. به جای آن از Query parameterها استفاده کنید تا شاخصها و معیارها را معین کنید.
فیلتر کردن
از Query parameterای که در URL میآورید برای فیلتر کردن منابع در سمت سرور استفاده کنید. برای مثال در صورتی که بخواهیم همه پستهای منتشرشده یک کاربر را استخراج کنیم، چنین APIای طراحی میکنیم.
GET /users/123/posts?state=published
در مثال بالا، state پارامتر عملیات فیلتر است.
جستوجو
به جای اینکه فقط به یک پارامتر فیلتر ساده بسنده کنیم، میتوانید برای جستوجوی پیشرفتهتر، از چندین پارامتر همزمان استفاده کنید تا منابع را از سرور بگیرید.
GET /users/123/posts?state=published&ta=scala
سرور با دریافت درخواست بالا، بین مطالب منتشرشده کاربر ۱۲۳، مطالبی که شامل تگ scala هستند را بر میگرداند.
جالب است بدانید که با کمک ابزار جاوایی Solr میتوانید باز هم جستوجوی قویتری فراهم کنید. با امکاناتی که Solr ارائه میدهد این بار میتوانید به شکل زیر APIتان را طراحی کنید.
GET /users/123/posts?q=sometext&fq=state:published,ta:scala
اینجا جستوجو برای تمام پستهای حاوی کلمه sometext صورت میگیرد که منتشر شدهاند و تگ scala دارند.
مرتبسازی
صعودی یا نزولی بودن مرتبسازی میتواند به شکل زیر در URL مشخص شود:
GET /users/123/posts?sort=-updated_at
در این حالت، مطالب بر اساس آخرین زمان آپدیت به شکل نزولی بر میگردند.
۹. HATEOAS
ابررسانه به عنوان موتور حالت برنامه (Hypermedia As Transfer Engine Of Application State)، یکی از اجزای برنامه تحت معماری REST است که آن را از باقی معماریهای تحت شبکه متمایز میکند.
HATEOAS به ما امکان مسیریابی راحتتر بین منابع و عملیاتهایشان را میدهد. با استفاده از این امکان، برنامه سمت کاربر نیازی نیست از پیش بداند چگونه برای عملیاتهای مختلف از API استفاده کند چرا که هر اطلاعاتی لازم دارد به شکل متادیتا در نتیجه درخواستهایش از سرور برمیگردد.
برای اینکه درک بهتری داشته باشیم بیاید به نتیجه درخواست زیر که مربوط به درخواست گرفتن کاربر 123 است توجه کنید:
{
“name”: “John Doe”,
“links”: [
{
“rel”: “self”,
“href”: “http://localhost:8080/users/123”
},
{
“rel”: “posts”,
“href”: “http://localhost:8080/users/123/posts”
},
{
“rel”: “address”,
“href”: “http://localhost:8080/users/123/address”
}
]
}
اما گاهی اوقات راحتتر است که قسمت links را نداشته باشیم و لینکها را به شکل فیلد معمولی مشخص کنیم مثلا:
{
“name”: “John Doe”,
“self”: “http://localhost:8080/users/123”,
“posts”: “http://localhost:8080/users/123”,
“address”: “http://localhost:8080/users/123/address”
}
این قاعدهای نیست که همواره رعایت کنیم و بستگی به فیلدها، مقدار اطلاعات و عملیاتهای مجاز روی منبعمان دارد. اگر منبعمان چندین فیلد مختلف دارد که احتمالا کاربر از آنها استفاده نخواهد کرد، بهتر است مسیریابی را به منبع زیرین نمایش دهیم و سپس HATEOAS را پیادهسازی کنیم.
۱۰. احراز هویت و صدور مجوز بدون نگهداری حالت
همانطور که میدانید، APIهای REST باید بدون نگهداری حالت (Stateless) باشند. هر درخواست باید به تنهایی اطلاعات لازم را داشته باشد که سرور بتواند بدون دانشی از درخواستهای قبلی، به درخواست جدید پاسخ دهد. در صورتی این امکان به وجود میآید که برای کاربران مجوز صادر کنیم. (Authorizing)
قبلا برنامهنویسان اطلاعات کاربر را در نشستهایی در سمت سرور ذخیره میکردند اما این روش مقیاسپذیری نیست. برای همین امروزه باید هر درخواست، همه اطلاعات لازم از جمله اطلاعات کاربر (اگر یک API امن است) را داشته باشد تا نیازی به تاریخچه درخواستها نباشد.
البته این مکانیزم، استفاده از APIها را محدود به افراد نمیکند، بلکه امکان احراز هویت سرویس به سرویس را هم به ما میدهد. برای احراز هویت کاربر از JWT (یا همان JSON Web Token) با OAuth2 استفاده میکنیم. برای احراز هویت سرویس به سرویس هم از API-key رمزنگاری شدهای استفاده میشود که داخل هدر قرار میگیرد.
۱۱. ابزار Swagger برای ساخت داکیومنت
Swagger ابزاری پراستفاده برای داکیومنت کردن APIهای REST است و این امکان را به برنامهنویسان دیگر میدهد که قواعد نحوی استفاده از API را هم به خوبی درک کنند. Swagger از شیوه اعلانی (Declerative) با کمک حاشیهنگاری (annotation) برای اضافه کردن داکیومنت به کد استفاده میکند و سپس این توضیحات تبدیل به JSONای میشوند که API و نحوه استفادهاش را بیان میکند.
۱۲. رعایت کدهای وضعیت HTTP
زمان برگرداندن نتیجه به سمت کاربر، از کدهای وضعیت HTTP استفاده کنید تا وضعیت نتیجه را مشخص کنید. ممکن است نتیجه موفقیتآمیز باشد یا درخواست ناموفق باشد اما باید دقیقتر مشخص کرد که موفقیت یا شکست از نظر سرور به چه معناست.
در زیر، نتایج مختلف بر اساس کد وضعیتشان گروهبندی شده و آمدهاند:
کدهای 2xx (موفقیت)
OK 200: زمانی که یک GET یا DELETE موفقیتآمیز باشد، این کد برگردانده میشود. البته PUT و POST هم در صورتی که نخواهند منبعی را پس از ساختن یا تغییر دادن به کاربر برگردانند، میتوانند از این کد استفاده کنند.
CREATED 201: موفقیت در ساخت یک منبع جدید که نتیجه یک درخواست POST موفقیتآمیز است.
کدهای 3xx (ریدایرکت)
Not Modified 304: در صورتی استفاده میشود که از هدرهای کش استفاده شود.
کدهای 4xx (ارورهای سمت کاربر)
Bad Request 400: این ارور زمانی برمیگردد که بدنه درخواست HTTP قابل خواندن برای سرور نباشد. مثلا زمانی که سرور انتظار دارد یک JSON به عنوان بدنه دریافت کند اما بدنهای که دریافت میکند یک JSON نیست.
Unauthorized 401: احراز هویت ناموفق بوده یا اصلا مدارک احراز هویت (مثل یوزرنیم و پسورد) ارائه نشدهاند.
Forbidden 403: کاربر با وجود احراز هویت موفقیتآمیز، اجازه این عملیات را ندارد.
Not Found 404: منبع درخواستشده روی سرور موجود نیست.
405 Method Not Allowed: در صورتی استفاده میشود که منبع مورد نظر کاربر موجود است اما این متدی که کاربر استفاده کرده روی آن پشتیبانی نمیشود. در این صورت سرور علاوه بر کد ۴۰۵، باید هدر Allow تحویل کاربر دهد که در آن متدهای پشتیبانیشده روی منبع مورد نظر وجود دارد.
کدهای 5xx (ارورهای سمت سرور)
ارورهایی که نشاندهنده خطای سمت سرور یا مشکلات زیرساختی هستند.
جمعبندی
برنامهنویسان و طراحان باید زمان کافی صرف طراحی APIهای REST کنند تا قابلیت استفاده راحت داشته باشد. همچنین باید APIها به خوبی داکیومنت شوند مثلا میتوان از مدل بلوغ ریچاردسون استفاده کرد.
منبع: این مطلب از وبسایت مدیوم که توسط جی کاپادنیس نوشته شده. (برداشت از مطلب فوق در تاریخ ۱ فروردین ۱۴۰۰ صورت گرفت.)
.
.
.
.
با ما همراه باشید
آدرس کانال تلگرام: JavaCupIR@
آدرس اکانت توییتر: JavaCupIR@
آدرس صفحه اینستاگرام: javacup.ir
آدرس گروه لینکدین: Iranian Java Developers




عالی بود مرسی
مطلب مفیدی بود.
با تشکر،
سلام
ممنون که مطالعه فرمودین.
سلام به سایت javacup
میخواستم شروع به یادگیری جاوا کنم و چند هفته پیش دیدم که ویدیو های آموزشی برای دانلود دارین. اما الان لینک https://javacup.ir/javacup-training-videos/ کار نمیکنه.
چی کار باید بکنم؟ اگه امکانش هست میشه لینک دانلود ویدیو ها رو بدین؟
سلام
الان به نظر میرسد که لینک ها کار میکنند، ممکنه مجدد چک بفرمایید؟